Are we analyzing data, or engineering reality?

Introduction
No worries, I didn’t choose this title to moan about how data science is not ‘true science’ (whatever that may mean). Rather, I hope to provide some different views of what it means to be a data scientist, which I hope will help in thinking how to take different perspectives when analyzing a problem. Originally, I was planning to call this essay “What I learned as a data scientist from Plato and the Nerd” [1]. Plato and the Nerd is a book written by Edward Ashford Lee that I recently came across. The title of the book does not really convey what the book is about. In a way, this does justice to Lee’s writing. He takes many interesting side paths — what he calls “nerd storms” — that the main message of his book remains opaque. In this essay, I’ll focus on one aspect of his book: the difference between science and engineering and how this collides with common thought in Data Science. Although Lee wrote the book for a general audience, I found the book especially useful to reflect on my own studies in computer science/information technology.
I guess this essay can be seen as a corollary of how Lee describes the difference between engineering and science. In particular, through the lens of Lee’s arguments, the common thought that “[Data science is a] concept to unify statistics, data analysis, informatics, and their related methods [in order to] understand and analyze actual phenomena [with data].” (emphasis mine) [2], which at the moment of writing is the first quote on the Data Science page of Wikipedia, seems to be a misconception. In the remainder of this essay, I will try to explain why, under Lee’s arguments, this is the case. I will do so by first taking a closer look at what we most often mean by this “actual phenomena”. Second, I’ll reflect on Lee’s distinction between engineering and science, which, given that we talk about data science, seems relevant. Last, I’ll philosophize on what this may mean to the work of data scientists.

Putting reality to the test (and why this is needed)
Lately I’ve been listening a lot to the BBC podcast ‘You’re Dead to Me’ [3], a history comedy podcast. An episode that I like in particular is one about the history of time keeping. In the episode, they talk about the many aspects of time that we currently take for granted. Even though I constantly use concepts of time, this episode made me realize just how little I knew (and know) about how these concepts came into existence. I just accept that an hour contains 60 minutes, that there’s a difference between work and leisure time, or that time exists in a continuum. All of these concepts about time are the visions of people that still echo through our culture without us realizing it. No wonder Lee refers to them as “unknown knowns”. Unknown knows also go under a different name: mental models.
An important task of science is to become aware of these unknown knowns, and test them against reality. The history of science is full of such examples. Before Copernicus, the common mental model was that the sun circulated around the earth. For a long time in our history, bloodletting, or the use of mercury, were considered medically sound. Statistics itself is also full of unknown knowns. Combining observations to improve accuracy, like the use of the mean instead of picking the most `reliable’ single observation, was rare and often criticized before 1750. When Euler tried to predict the motions of Jupiter and Saturn, he used the data points he considered most likely, instead of using an average over all the data to predict [4, p.p. 25–31]. In another example, 19th century economists had to defend themselves against legal charges when combining the prices of several products into one index [4, Ch. 1], even though at that time, statistical methods were widely used among astronomers.
For a data scientist, testing mental models against reality seems to be at the core of one’s activities. This is not only true for trivial examples, like A/B testing, but also in forecasting and optimization. People have a strong tendency to connect pieces of information to make a coherent story, even if these pieces of information are actually disconnected (the so-called hindsight bias). Once such a story is in someone’s head, it can be difficult to change it. In fact, the confirmation bias would suggest that the person will mostly look for evidence supporting the story. Even if you can show that a forecasting model is more accurate, or that a planning algorithm performs superiorly compared to what a human can do, you will always find people arguing that the model does not work in this or that exception. Or that, as the model may be a black box, it cannot be trusted. I personally experienced this with the recent developments around ChatGPT. It’s difficult to accept that this software may write this blog, given only a few words of instructions, perhaps better than I would. This only makes me think of reasons why ChatGPT must be inaccurate, unsafe, or unreliable. The idea that a model you create will be perceived with an open mind is an illusion. You always have to compete with already existing models, whether mentally or physically.
One of my favorite quotes about testing mental models against reality comes from Croll and Yozkovitz in their book Lean Analytics [5]:
“We’re all delusional — some more than others. Entrepreneurs are the most delusional of all. […] Lying may even be a prerequisite for succeeding as an entrepreneur — after all, you need to convince others that something is true in the absence of good, hard evidence. You need believers to take a leap of faith with you. You need to lie to yourself, but not to the point where you’re jeopardizing your business.
That’s where data comes in.”
Data is used as a mirror to validate mental models against reality. We therefore call it data science. A scientist, in Lee’s words “choose[s] (or invent[s]) a model that is faithful to the target”. The quote by Croll and Yozkovitz also highlights that creating mental models based on prior beliefs is not something bad per se: self-deception is a fine line. On the one hand, it can be important to fool yourself that you are able to do something. Take the imposter syndrome, that feeling that people have that the success they achieved is just luck, and that they can be exposed as frauds any minute. You need to “fake it ‘till you make it”, in order to overcome such cognitive bias. On the other hand, many are too confident of their decision (e.g., the Dunning Kruger effect). Your ego either avoids you from doing what you should be doing, or gets in the way of recognizing that you shouldn’t be doing what you’re doing.
What makes self-deception extra difficult is that in a way it is not lying, in the sense that these cognitive biases make you actually believe that your mental model is reality, and you won’t just accept any argument that tells you differently [22, p. 490–492]. This is what makes data science hard: sometimes you can have all the evidence, but if this is contrary to the mental model of the decision maker, you will have a difficult time convincing that person. As the saying goes: the role of a data scientist is to tell people that their baby is ugly, people are usually not very happy to hear that.
So, this was my mental model of what it meant to be a data scientist, until Plato and the Nerd took it apart.

Reality is a stack of mental models
If you take another look at the previous paragraph, you’ll find that what I just called ‘reality’ is loaded with yet another stack of mental models. The “Lean” in Lean Analytics refers to the mental model by Eric Ries’ Lean Startup [6], which advocates a method of quick entrepreneurial trial and error for rapid growth. Hopefully, this will lead to the company being large enough to going public. Subsequently, the idea that businesses need to quickly ‘scale up’, is likely to be inspired by the successful business models from Silicon Valley’s exponential organizations [7] (even though only 0.4% of all start ups actually scale [8]).
Looking further into history, the idea that companies need to grow is clearly a capitalistic one, originating from, among others, the thoughts of the 18th century Adam Smith. The idea of a public firm is a 17th century invention of the Dutch East-India Company (VOC) [9], coming from a country that at that time itself had only recently been invented, after having been forged by four generations of Burgundian rulers . Perhaps most interesting is the concept of money itself, about which Lee refers to Searle [10 p.78] in that money is “whatever people use and think of as money”.
Like anyone who has ever had a discussion with a six year old may have witnessed, we can keep continuing peeling off mental models by asking ‘why’, just to arrive at new ones. Until, at some point, you arrive at certain mental models that seem to be the axioms of your own thinking. But here is the catch: all these models are, well, models. They are not reality. Even fundamental models like quantum mechanics are inaccurate when considerings these on a large scale.

Why a data scientist is an engineer
You are surrounded by mental models, which is where the engineer enters the story. Lee writes about the difference between a scientist and an engineer:
“We can either choose (or invent) a model that is faithful to the target, or we can choose (or invent) a target that is faithful to the model. The former is the essence of what a scientist does. The latter is the essence of what an engineer does.” P.197.
As an example, Lee gives the transistor. The transistor is a model of an off/on switch. That is, transistors are not really off/on switches: they are amplifiers. Transistors simply have been created in such a way that they are close approximations of off/on switches. The target (the transistor) is faithful to the model (an off/on switch). Following the above definitions of an engineer and scientist, the creation of the transistor is an engineering job. What is more, Lee shows that also electromagnetic laws such as Faraday’s law, which would describe the “real behavior” of transistors, are in fact models. Only in certain situations does reality obey these models; in others, they can be plainly wrong. In fact, science seems to be a stack of models, each building on the approximations of the previous. This only ends when at a certain level of abstraction reality becomes unfaithful to the model. As Lee shows in Chapters 2–6, the stack of models in computer science, from transistors to websites, seems almost endless.
Economic models are no different. Next time you meet someone, ask that person whether you can borrow their pen. Surprisingly, most people will not ask you for a fee or will even insist on you keeping the pen. Within certain contexts of human interaction, a form of “everyday communism” seems to be the prevailing way, not capitalism [11, pp. 94–102].
But Lee continues in arguing that, in fact, most of what we call science is engineering.
“But more fundamentally, the title [Plato and the Nerd] puts into opposition the notion that knowledge, and hence technology, consist of platonic ideas that exist independent of humans and is discovered by humans, and an opposing notion that humans create rather than discover knowledge and technology. […] The nerd in the title is a creative force, subjective and even quirky, and not an objective minor of preexisting truths.”
After reading this, I had the feeling that I had perhaps chosen the wrong profession. To me, the concept of Data Science was precisely the ‘discovery’ part. One should grind through data as an independent observer, coming up with ‘insights’ that help the organization add ‘value’. Following that concept, the data scientist is like Agatha Christie’s Poirot, the inspector who seeks out evidence to solve the mystery, but who isn’t part of how the murder is plotted. And, of course, once the mystery is solved, it is revealed to the audience (for the data scientist, in a somewhat less spectacular Power Point presentation), who awe at the brilliance of the solution. True, this is a bit exaggerated, but the idea that the solution should be complex and be discovered by white men with glasses is certainly part of another mental model [12]. Following Lee’s definition of a scientist, our Data Science Poirot indeed does describe someone who invents a model faithful to reality, hence a scientist.
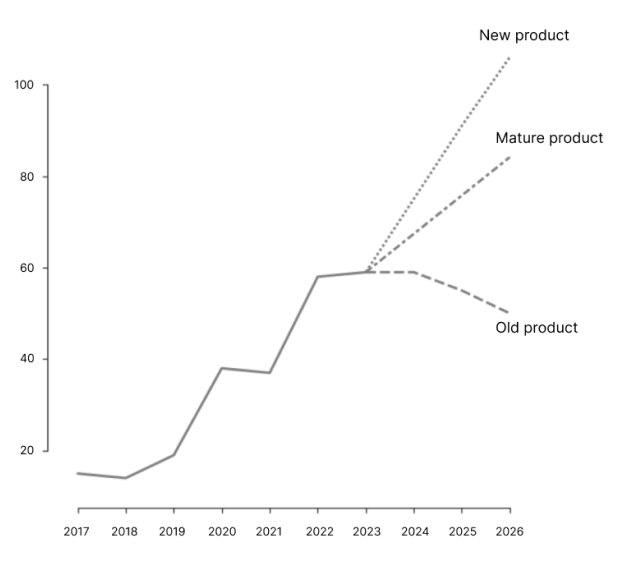
But now consider the following problem: you’re given some historic sales data (see figure below) from a relatively new product of which you and many others are almost certain sales will grow in the near future. What forecast will you make? Will you just ‘let the data speak’: fit a linear model, and extrapolate to the future? Or will you use this information to define some model with exponential growth over the next few years? Say you choose the latter, make the prediction, and share it with the business owner. The business owner subsequently decides to kickstart the marketing machine to make the prediction happen. Your prediction by now has become a business target, sales increase and even surpass your forecast. Following Lee’s discussion about engineers and scientists: were the business results engineered? Or were they some inevitable science?
This example comes from Planning and Forecasting in the 21st century by Makridakis [13]. In his book, he describes an experiment where business owners are asked to make forecasts based on some historic sales data. Along with the data, they are told that the product is either old, new, or mature. As can be seen from Figure 1, the forecasts were drastically different. None of these forecasts is inherently wrong; they follow the mental model of a product life cycle. It simply shows that even with the same data, forecasts can be completely different, which subsequently impacts actions and outcomes. Did our data scientist solve the murder, or commit it?
The reality is that as a data scientist, you play an important role in the definition of ‘value’ (the model). You have discussions with the business on how they can add value through data. You play a role in the definition of KPIs. If no financial benefit can be found, then there is often something else that benefits from the data analysis. A successful data scientist, on many occasions, is indeed someone who knows how to change behavior (e.g., that of customers), to be faithful to a certain model (e.g., optimizing revenue). Of course, one can only bend reality that much. Changing human behavior can be difficult. But, not realizing that, as a data scientist, you can, and probably already are bending ‘reality’, would be a mistake. A data scientists is an engineer.
Engineering reality
“Well, if the rules of the game force a bad strategy, maybe we shouldn’t try to change strategy. Maybe we should try to change the game.”
This quote comes from the book Algorithms to live by [14, p. 240]. In a chapter on game theory, the authors discuss the Vickrey auction [15]. The Vickrey auction is a so-called second-price auction, as the winner pays the amount of the second-place bid. In the Vickrey auction, the dominant strategy for each player is to bid true to the value he/she considers the item to be worth, instead of, say, bluffing to make another party pay a high price. The Vickrey auction is in that sense an example of how one can change behavior to be truthful to a preferred model.
In practice, there are many more ‘preferred models’. A common property of a model is, for example, one with little randomness. Whether that be in manufacturing and logistics under the name ‘six sigma’, or in customer service’s ‘effortless experience’ [16]. If the model is capable of coping with randomness, it’s easier to analyze and make decisions based on it. It is here that the probabilistic background of the data scientist comes of value. One can reduce the randomness by explaining some of the randomness using a statistical model, use techniques like simulation to determine how well a model copes with uncertainty, or point out that perhaps business owners are focusing too much on volatile day-to-day performance and not seeing the more stable long-term patterns. As Lee’s example of the transistor and subsequent layers of abstraction shows, decreasing randomness is incredibly important in order to build subsequent layers of abstraction. When I’m programming in Python, I don’t have to think about how exactly the program is executed on my machine, and I take it for granted that the program is perhaps not as fast as it could have been, had it been programmed in a language closer to machine code.
But reducing randomness is also risky. Many crises occur when some assumption at a lower level of abstraction is violated. Take logistic supply chains for example. In the last decade, the philosophy of six sigma has been a prominent strategy for managing parts of supply chains. But longer supply chains are bound to induce more randomness. Small disruptions may be smoothed by using buffers, but this is not the case for large disruptions, which have been frequent since the Corona crisis [17]. As a consequence, research has increasingly looked for ways to prepare for disruptions, rather than try to reduce them [18]. Also here, the data scientist has an engineering role. Will he/she explain the observed variance as something to be reduced, or should it be accepted as something unavoidable? Explaining one over the other will, just like in the forecasting example, lead to different strategies: a tight vs. a robust process.
The concept that data scientists are engineers also returns in the frequent ethical discussion on data and AI. Although nudging customers to buy/click/spend more may on many occasions be harmless, sometimes it is less so. One shocking example is described by Schüll [19]. Schüll studied the addictiveness of slot machines in Las Vegas, including how the engineering of the slot machine contributes to the addiction, and of which many principles apply to other digital devices such as mobile phones. In one bizarre example, someone in a casino gets a heart attack. While paramedics try to save her, other visitors of the casino just continue playing their slot machines. The slot machines have been optimized in such a way that users remain in their ‘flow’, even when their neighbor drops dead to the floor.
Of course, one can argue whether it is to blame the engineer who ran the A/B-tests that made slot machines so addictive, but I hope that so far I’ve convinced the reader that I believe this is at least partly the case. On the bright side, although slot machines are still as addictive as ever, the media attention on algorithms gone wrong has increased attention on things like algorithm fairness [20]. Important public algorithms (such as search engines) are more often under scrutiny by algorithm audits [21]. Under the motto “you can’t manage what you can’t measure”, if you include measures of fairness into your analysis, the decision maker will have to explain why he/she might have ignored that measure. If no measure of fairness is reported, the decision maker may not realize that there is a fairness issue in the first place.

Conclusion
The emphasis on analysis is everywhere in descriptions of data science and analytics, but should it be invention instead? In the Gartner analytical maturity curve, one only starts with ‘prescriptive analytics’ once the descriptive and predictive analytics (which just analyze phenomena) stages have been completed. However, in many applications, one may find that behavior (the actual phenomenon) has been adjusted to a model (revenue, fairness, etc.), not vice versa. Although some systems and technologies are more user-friendly than others, one cannot help but recognize that, for a considerable part, people have adjusted to technology. Yes, I find Google a user-friendly search engine, but I’ve also become trained in searching for the right keywords that may take me to the right webpage. I learned how to drive and to look out before I cross the street, the latter which contributed as much to efficient transportation as the invention of the car itself.
Of course, there are situations where as a data scientist you are just analyzing the phenomenon. Where you are just playing the part of Poirot, only investigating the murder. But knowing that behavior often follows technology, rather than the other way around, is useful to a data scientist. Instead of analyzing actual phenomena, one may think about what a preferred phenomenon may look like and design models accordingly.
References
[1] Lee, Edward Ashford, Plato and the Nerd: The Creative Partnership of Humans and Technology (2017), MIT Press
[2] Hayashi, Chikio,What is data science? Fundamental concepts and a heuristic example. Data science, classification, and related methods (1998), Springer, Tokyo, 40–51. Via Wikipedia: https://en.wikipedia.org/wiki/Data_science. Parts between brackets are from the Wikipedia page, the rest is quoted from the original paper. Last accessed: 02–04–2023.
[3] BBC, The History of Timekeeping (2022), You’re dead to me, BBC, Retrieved from: https://www.bbc.co.uk/programmes/p07mdbhg, last accessed 02–04–2023.
[4] Stigler, Stephen M. The history of statistics: The measurement of uncertainty before 1900. Harvard University Press, 1986.
[5] Croll, Alistair, and Benjamin Yoskovitz. Lean analytics: Use data to build a better startup faster. O’Reilly Media, Inc., 2013.
[6] Reis, Eric. The lean startup. New York: Crown Business 27 (2011): 2016–2020.
[7] Ismail, Salim. Exponential Organizations: Why new organizations are ten times better, faster, and cheaper than yours (and what to do about it). Diversion Books, 2014.
[8]: ScaleUpNation. The Art of Scaling. 2020. https://scaleupnation.com/wp-content/uploads/2021/02/The-Art-of-Scaling-3.1.pdf. Last accessed: 02–04–2023.
[9] VOC. Retrieved from: https://en.wikipedia.org/wiki/Dutch_East_India_Company last accessed: 02–04–2023.
[10] Searle, J. Minds, Brand and Science. Harvard University Press, Cambridge, MA.
[11] Graeber, David. Debt: The first 5000 years. Penguin UK, 2012.
[12] Chang, E. Brotopia. Penguin, 2019.
[13] Makridakis, Spyros. Forecasting, Planning, and Strategies for the 21st Century. Free Press, 1990.
[14] Christian, Brian, and Tom Griffiths. Algorithms to live by: The computer science of human decisions. Macmillan, 2016
[15] Vickrey auction. Retrieved from: https://en.wikipedia.org/wiki/Vickrey_auction, last accessed: 02–04–2023.
[16] Dixon, Matthew, Nick Toman Rick DeLisi, and N. Toman. The Effortless Experience. Penguin Random House, 2020.
[17] Congress Research Service. Supply Disruptions and the U.S. Economy . 2022. Retrieved from: https://crsreports.congress.gov/product/pdf/IN/IN11926, last accessed: 02–04–2023.
[18] Spieske, Alexander, and Hendrik Birkel. Improving supply chain resilience through industry 4.0: A systematic literature review under the impressions of the COVID-19 pandemic. Computers & Industrial Engineering 158, 2021.
[19] Schüll, Natasha Dow. Addiction by Design. Princeton University Press, 2012.
[20] Pitoura, Evaggelia, Kostas Stefanidis, and Georgia Koutrika. Fairness in rankings and recommendations: an overview. The VLDB Journal, pages 1–28. Springer, 2022.
[21] Bandy, Jack. Problematic machine behavior: A systematic literature review of algorithm audits. Proceedings of the acm on human-computer interaction 5, CSCW1, pages: 1–34. ACM 2021.
[22] Pinker, Steven. The better angels of our nature: The decline of violence in history and its causes. Penguin uk, 2011.
No ‘Science’ in Data Science? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.