Revolutionising Efforts with Generative Adversarial Networks and Synthetic Data
Introduction
The recent explosion of generative Artificial Intelligence (AI) models has focused the world on ethics, risks, and security concerns, and the Bletchley Park conference earlier this month cumulated in a commitment to international collaboration on the safety of emerging AI systems. Yet, those same systems can help address similar challenges to ethical engagement in others.
Government corruption and systemic bias are formidable barriers to thriving societies but are difficult to tackle. Synthetic data and generative AI in the form of Generative Adversarial Networks (GANs) offer the possibility not only a way to seek out corrupt practices, but also to pre-empt innovations in how corruption takes place.
The Prevalence and cost of Corruption in Government
Transparency International’s Corruption Perceptions Index consistently illustrates the pervasiveness of this issue across governments. Its myriad forms can include patronage, bribes, nepotism, manipulation of evidence, kickbacks, and similar behaviours designed to provide advantages through the abuse of function. There is a significant financial cost, and the World Bank has projected figure at 2.6 trillion USD each year, with roughly one trillion USD paid in bribes annually worldwide. This is already substantial, but the effect of corruption extends much further. Corruption damages trust in public institutions, erodes respect for laws, threatens basic services such as education and health, and takes away vital funds needed to tackle climate change. The gains for those involved (or turning a blind eye), and the potential for personal security risk acts as a strong deterrent for witnesses coming forward. AI offers an important tool to empower anti-corruption units.
AI use in anti-corruption
AI comes into its own when trying to make sense of complex data that has an intricate web of interconnections. Whilst not widespread, examples exist of AI identifying criminal and corrupt behaviour.
In 2017, Spanish researchers Félix López-Iturriaga and Iván Pastor Sanz used neural networks to build a predictive model for corruption in Spanish provinces. They used real-life data from a corruption case database created by the El Mundo newspaper, analysing the years leading up to any convictions, to identify potential early-warning signs. This enabled the AI model to uncover unseen relationships and connections, such as rising real estate prices and corruption cases.
The use of AI to spot suspicious behaviour and guard against fraudulent activities is already widespread in the banking sector.
Ukraine’s system to identify risks in procurement (PROZORRO) uses a programme called DOZORRO designed to identify potential misconduct in public procurement. The data to train the AI cames from risk assessments carried out by experts on around 3,500 tenders. The system could then independently assess corruption risks in tenders and share the findings with civil society watchdogs. Initial findings suggest billions of dollars have been saved, the government is more legitimate, and — vital in the current context — foreign companies are more likely to invest.
The World Bank launched a AI-based Procurement Anti-Corruption and Transparency platform (ProACT) in 2021. Using data from open sources across over 100 countries, it allows anyone to search and review public procurement contracts, their transparency rating, and potential integrity risks.
AI systems, however, rely on data, and the scarcity of reliable data in corruption studies is a well-documented challenge. It can be difficult to obtain accurate data due to the hidden nature of corrupt activities, records not containing the right data or containing errors, or a lack of knowledge around new approaches and systems to defraud.
Synthetic Data
A possible aid for many of these problems is the use of synthetic data, which is artificially generated data that is created through algorithms, rather than being collected from real-world events or processes. It mimics authentic data, making it useful for training machine learning models when actual data is either unavailable, insufficient, or sensitive. Models can learn and adapt in environments mirroring real-world corruption scenarios, all without risking privacy breaches, or compromising sensitive data.
Given the level of complexity in corruption networks and the scarcity of data, synthetic data offers a level of granularity that is essential for training AI to detect nuanced patterns of corruption that do not show up in simpler datasets. By building realistic datasets, AI systems are equipped with tools to explore, understand, and predict.
These high-quality, fictional data sets can train AI systems in diverse and intricate scenarios. This approach increases the safety and anonymity of individuals involved in sensitive investigations and provides the complexity for AI to recognise and predict patterns of corruption.
Furthermore, research suggests that AI systems trained on synthetic data can achieve accuracy levels comparable to those trained on real-world data, but in a fraction of the time and without the ethical and legal complications often associated with real data usage. This means that training AI with synthetic data is efficient, and more likely to keep up with the pace of change by criminals (who also use AI to strengthen their approaches).
Generative Adversarial Networks (GANs): The Core Technology
GANs are a type of AI technology used to generate synthetic data that employ two neural networks — the Generator and the Discriminator — in a dynamic process where each network learns by trying to outwit the other.
Having been trained on limited real data, the Generator creates synthetic detailed corruption scenarios, while the Discriminator tries to determine whether what it is examining is real or fake (again initially drawing on its own limited real data training). The initial creations are likely to be crude, with the Discriminator easily identifying the right answer. However, the Generator learns from this, and improves its productions. As the Generator’s data becomes increasingly realistic, the Discriminator’s ability to differentiate also sharpens. This iterative process continues until the final synthetic data is a close replica of actual and potential real-world scenarios, and nuanced patterns of corruption.
The data that emerges from this circumvents the problems associated with real-life data mentioned above, especially regarding limited availability constraints and privacy/secrecy of the data. This synthetic database is then used as the basis for training specific AI systems to carry out the corruption prediction, detection, or analysis work.
The difference with GANs-generated synthetic data
The increase in quantity and complexity in GANs-generated synthetic data enables governments and regulatory bodies to improve their detection capabilities, making them more adept at identifying subtle and complex forms of corruption that might otherwise go unnoticed.
By simulating a wide range of corruption scenarios, GANs help to create AI tools that are both reactive (spotting corrupt incidents), and proactive (identifying developing real-life scenarios that have increasing likelihoods of leading to corruption). AI systems trained on the synthetic data can learn from a wide variety of potential corruption scenarios, including those that might not be well-represented or available in real-world data. This means that the AI system increases its understanding of corruption patterns and develops more robust and intelligent systems to fight against it
The World Bank has identified several ways corrupt behaviour might evolve, including the introduction of complex data patterns and digital platforms to conceal corrupt activities, the use of professionals (bankers, lawyers, and accountants) as facilitators across sophisticated networks, and more intricate methods of corruption to circumvent new international standards.
As the capacity to undertake corrupt activities grows, anti-corruption efforts also need to become more sophisticated. The speed with which AI can generate, test, and re-generate scenarios, and the range of settings it can create, opens up the possibility of keeping up with — or even overtaking — the pace of this change.
Ethical Dimensions and Privacy Concerns
Whilst synthetic data use mitigates privacy risks, the initial training phase to develop it requires real data from governmental records, audit reports, compliance data, public sector databases, legal and regulatory documents, and whistle-blower reports and complaints. This understandably raises several risks:
1. Sensitive Information: Data processed within a governmental context often includes personal details, confidential government files, or sensitive financial records. Information in procurement bids is invariably commercial in confidence.
2. Embedding Bias: Any biases or discrimination (explicit or implicit) contained in the initial data can influence the subsequent system. For example, prior gender or racial discrimination in decision-making, appointments, or roles — however subtle — will be taken as part of the baseline “truth” on which the machine builds its knowledge.
3. Risk of Misuse or Data Breaches: Government AI systems could be targeted for malicious purposes, due to their access large, potentially confidential datasets, leading to data breaches or misuse of information.
4. Ethical AI Development: As AI systems are trained to detect patterns of corruption, they must do so without infringing on individual rights or creating new ethical dilemmas.
5. Legal Compliance: Stringent data protection laws increasingly govern handling personal data (e.g. GDPR).
6. Maintaining Public Trust: Trust in public institutions can be eroded if AI tools are perceived to be infringing privacy or unethical.
Concrete actions to mitigate the risks listed above include complying with applicable legal frameworks, implementing robust privacy safeguards, expert reviews of learning data for biases, safeguards for the use of personal data, and transparency for the public in how ethical norms are being upheld. A proactive approach will increase the legitimacy and trustworthiness of the AI being developed and reduces the risk of any subsequent corruption prosecutions being undermined by challenges to the systems used.
Introducing GANs and synthetic data into government anti-corruption systems
The following diagram provides an example of where GANs and generated synthetic data would be introduced in an AI corruption detection system.
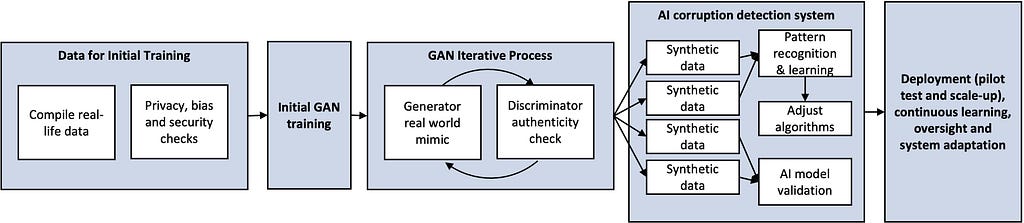
- Data for initial training: This involves identifying government sectors prone to corruption, potentially drawing on external anti-corruption civil society to provide expertise. Historical real-life data on corrupt and non-corrupt situations from across these areas is then checked against ethical safeguards.
- GAN creation, training, and operation: The GAN model receives initial training based on real-world data and is then left to run the interactions between its two networks to produce synthetic data.
- Train and Refine AI Detection Models: The synthetic data produced by the GAN is used to train a new AI model in detecting patterns indicative of corrupt activities.
- On-going monitoring for ethics and bias: Whilst synthetic data vastly reduces the risk of bias and privacy concerns, there is still a possibility that residual problems emerge.
- Pilot Test: Initial testing can be carried out using AI models deployed in controlled environments to evaluate their effectiveness in identifying corrupt practices (with feedback being provided to the GAN to adjust).
- Scale up: Models are integrated into wider governmental systems (again maintaining continuous oversight and adjustments as needed).
- Continual Learning and Adaptation: Findings from the AI corruption detection system can be fed back into the GAN, passing first through the same process used earlier to check for bias and remove any privacy or security concerns, to ensure the system remains flexible and adaptive to new corruption tactics and evolving data landscapes.
Conclusion
The use of synthetic data created using Generative Adversarial Networks (GANs) is a methodical approach to combating corruption that goes beyond detecting current practices to predicting and adapting to emerging trends. Using a continuous, iterative learning process, the system can potentially identify and adapt to future methods for corruption. The scarcity of data on corruption — in particular the level of detail that allows detection systems to pick up on increasingly subtle indicators, potentially spread over multiple jurisdictions — is mitigated by the ability of GANs to develop new data for a wealth of different scenarios.
Ethical concerns persist, albeit substantially reduced, hence safeguards and monitoring remain paramount. As a cornerstone of good governance, governments and regulatory bodies need to maintain transparency and accountability as an overarching priority.
Despite its infancy, the potential AI in the fight against corruption is significant. The pace of innovation in corrupt practices is accelerating, with AI deployed to create increasingly opaque and convoluted networks designed to circumvent classic tools of detection. Government anti-corruption agencies need to maintain — as a minimum — a similar trajectory of invention and investing in GAN-generated synthetic data provides an opportunity to predict and therefore mitigate. Moreover, with trillions lost per year to corruption, developing AI in an area where success can lead to a direct increase in budgets for public spending, pursuing such an investment enables governments to deliver on providing for their people.
AI’s Proactive Role in Outsmarting Corruption in Government was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.