Tools and techniques for data cleaning, visualization, augmentation, and synthetic data generation

Smart Data over Big Data. That’s the postulate of the “Data-Centric AI” paradigm.
More than just “simply preprocessing” data, data scientists should a build a continuous and systematic practice of understanding and improving their datasets.
This will ultimately drive our focus from blindly pursuing higher classification results by throwing ever more complex algorithms to the problem to a deep understanding of why the classification results are what they are, what is indeed the source of complexity of the problem, and how we can adjust the data so that classifiers can learn the problem better, thus increasing their performance.
If you’re new to machine learning, this might seem a little bit daunting: “What are the best practices of building high-quality datasets and how to put them in place?”
In this tutorial, we’ll go through a simple case of leveraging the Data-Centric AI paradigm to achieve high-quality data and improve our machine learning classification results.
Following the mantra of Data-Centric AI — it’s all about the data—at no point will we delve into the model itself (honestly, it will be a simple decision tree).
We’ll use the Pima Indians Diabetes Dataset , freely available on Kaggle (License: CC0: Public Domain). You’ll can also find all the code and additional materials at the Data-Centric AI Community GitHub.
Shall we get started?
Step 1: Performing Data Profiling for Data Understanding
Before we start curating our dataset, we need to understand the problem we’re trying to solve and the peculiarities of the data we’re working with. Thoroughly understanding our data characteristics, problem complexity, and use case domain is one of the first principles of Data-Centric AI.
This will help us determine the next steps to move along your machine learning pipeline.
When it comes to data profiling, there are several interesting open-source tools that you can explore: I’ve made a review of a few myself, including ydata-profiling, dataprep, sweetviz, autoviz, and lux.
I currently use mostly ydata-profiling: I find it to be a top-notch tool for data practitioners that, rather than making us jump through pandas hoops to get the most of our data’s characteristics and visualizations, lets us do it all in a few lines of code.
First, you’ll need to install ydata-profiling (better use a virtual environment for this — if you don’t know how, you can check this 2-min video, or this full tutorial if you’ve never worked in conda environments before):
https://medium.com/media/3a2ba63233f47af25d6ed71911273952/href
Then, we can get a complete overview of the data by saving a .html report of all the characteristics and visualizations we need to get started:
https://medium.com/media/41a3bec9c334f78504da1f658f2d3139/href
The data report let’s us know immediately the overall characteristics of our data and highlights some warnings that we might need to take into account:
The datasets contains 768 observations and 9 variables/features. While 8 are numeric, 1 is identified as categorical (Outcome seems to be our target). There are no duplicate rows and apparently there are no missing values. Finally, some High Correlation warning sare found among the the features. Moreover, several features have a large number of Zeros.
Now it’s time to play data detective. High Correlations are rather expected in biological features, but how about these Zero values?
Looking at some of the features highlighted (e.g., BMI), we can see that these values are quite far off from the overall distribution. And resorting to domain knowledge, these “0” values are actually nonsensical: a 0 value is OK for Pregnancies but for BMI, Glucose, Insulin, Blood Pressure, or Skin Thickness is invalid.

We quickly realize what these zeros are encoding: missing data.
For now we’ll get on fixing this issue, but a thorough process of EDA can comprehend a lot more. Check this Essential Guide to Exploratory Data Analysis to see what else you could uncover from your data.
Step 2: Investigating Data Quality Issues
Now that we found that some columns have invalid zero values, we can start by handling the missing data issue on our dataset.
Many machine learning models and scikit-learn estimators do not natively support missing values, so we need to handle these NaNs somehow before feeding our dataset to the estimator.
First, lets mark these 0 values as NaN values:
https://medium.com/media/91374bfd39d6d5a16a6dc159f9fef03a/href
Now, we can use data imputation to replace the NaN observations with plausible replacement values.
The “no free lunch” theorem tells us that there is no best solution for every situation — we should investigate how different solutions affect the complexity of our training data and determine what boosts our machine learning model the best. That’s actually another principle of Data-Centric AI: constant iteration and improvement.
For now will use a very simple method — SimpleImputer — to replace the zero values with the mean value of each feature. This is a very naive approach that is likely to create some undesired “spikes” in our distributions, but the goal is simply to showcase how to highlight and impute missing data, we can try better approaches later on:
https://medium.com/media/3626d84afaf84eb98a7464fc70b9016e/href
Now, we can then try out a very simple decision tree classifier and see what would be the baseline of our classification results. As a side note, decision trees can be extended to support missing values naturally, via surrogate splits or other methods. Indeed, in scikit-learn’s documentation seems like decision trees do have built-in support for missing values in some conditions in the current version ( 1.3.2). However, as I was using version 1.2.2 , I stumbled upon this error:

Still, even if the NaN values are dealt with internally, training your models with missing data is not a good practice, as it will jeopardize the concepts that the model learns from messy and limited information.
https://medium.com/media/7309eed6d7bf026f9b4df96e136cd582/href
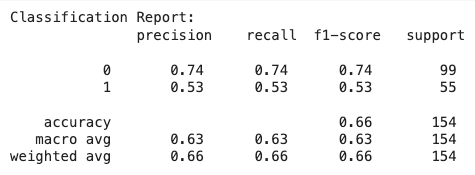
Here’s the confusion matrix:
https://medium.com/media/04544466ed622a75616220b0d4a20631/href
The classification results are not great. Keep in mind that we’re using a simple decision tree, but still… there is a significant different between the prediction for our target categories. Why is the classifier performing better for class “0” than class “1”?
Step 3: Augmenting Underrepresented Classes
If we were paying attention in Step 1 (maybe you’ve discovered it already), our target class, Outcome, is imbalanced. Maybe not at the point to trigger a warning in the default settings (the default threshold is 0.5), but enough to still bias the classifier towards the majority class, neglecting the minority one. This is clear from the data visualization presented in the Profiling Report:
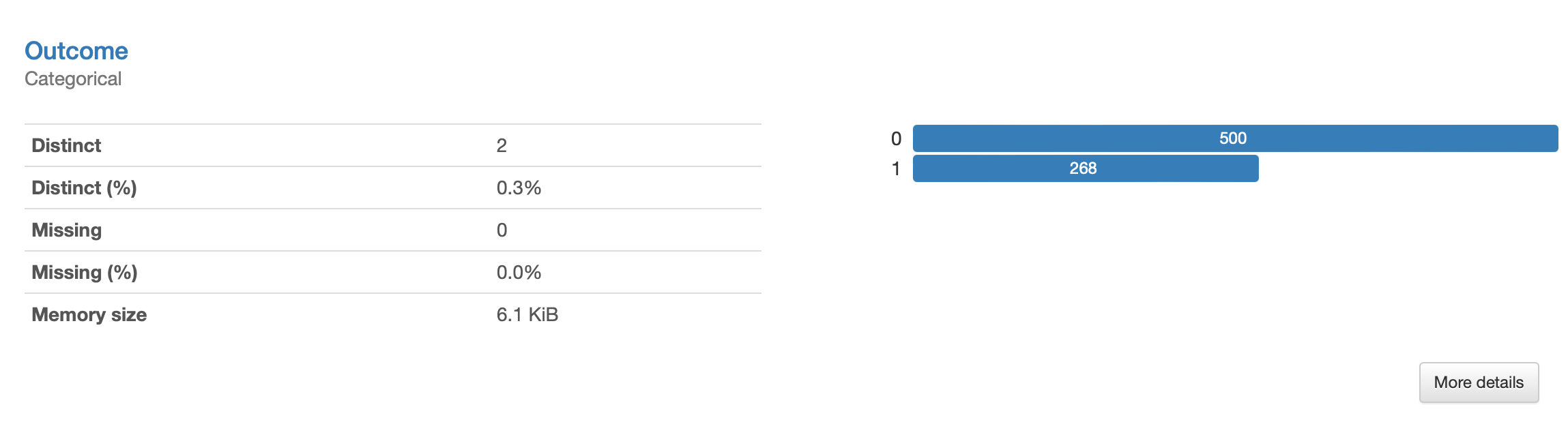
Note that while missing data can be caused by several errors during data collection, transmission or storage, the class imbalance may reflect a natural characteristic of the domain: e.g., there are simply less patients diagnosed with diabetes in this medical center.
Nevertheless, it is still important to act over the training data to guarantee that the model does not overlook the minority cases: in fact, that’s what we’re trying to predict more accurately.
A false positive is bad since it will give the wrong information to a healthy patient the she has diabetes. But when additional tests are made, this will be just a “scare”.
However, in this case, a false negative is worse. We’d be telling a patient with diabetes that everything is OK, she passes undiagnosed, and the disease progresses.
One way to increase these numbers is by using data oversampling techniques. Data Oversampling is a popular technique among data practitioners to adjust the distributions of a dataset — i.e., the ratio between the existing classes or categories in data — thus mitigating the imbalanced data problem.
And is just one of many interesting and useful applications of Synthetic Data.
While synthetic data can have several interpretations — e.g., “fake data”, “dummy data”, “simulated data” — here we’re referring to “data-driven” synthetic data generation.
In that sense, synthetic data is artificially generated that that preserves the characteristics of real data — its structure, statistical properties, dependencies, and correlations.
There are a plethora of methods and open-source tools to generate synthetic data — ydata-synthetic, sdv, gretel-synthetics, nbsynthetic, and synthcity are just some that I’ve experimented with in the past.
And again… there are “no free lunches”: choosing the most appropriate method will invariably depend on the objective for which the synthetic data is needed.
To have a quick grasp of how synthetic data can be used for augmentation, we’ll leverage the ydata-synthetic package, and experiment with their Gaussian Mixture Models.
First, we’ll need to install the package:
https://medium.com/media/cd9c5c899baedfb25c5942e20789f188/href
And once that’s done, creating synthetic data is super straightforward:
https://medium.com/media/611eb39043fa839b9f190f64def10425/href
After we have our synthetic data, we can simply take out a subset of the newly generated minority class samples generated by sampling from the synthetic data, and add it to the training data to create a balanced (i.e., 50%-50%) distribution:
https://medium.com/media/bc876c122504b1ff89546ae0b567abfb/href
Let’s see how that impacts the learning of our decision tree and its subsequent results:
https://medium.com/media/01702bf7af25824b7a1f9e4918eabbb2/href
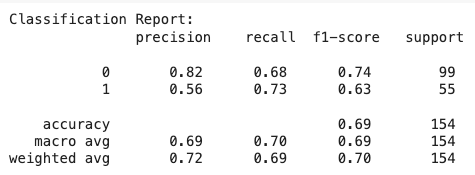
And the confusion matrix:
https://medium.com/media/405d8bef542edd0ae02ab9848e3f9b8e/href
Note how such a simple modification of our training set resulted in a performance boost of our F-score in 10% and a significant improvement of the minority class sensitivity results (from 53% to 73%).
Here lies the beauty of the Data-Centric AI paradigm: without ever touching our model parametrization, we’ve significantly improved the quality of our training set with very simple heuristics and standard techniques — imagine what we could do with more advanced strategies and specialized data preparation pipelines!
Sure, class 0's recall suffered a bit, but ultimately, we need this model to be more sensitive than specific (i.e., detect better the positive class than the negative class) due to the particular constraints that we’re dealing with: disease diagnosis — again, another principle of Data-Centric AI: methods and results need to be evaluated based on the domain’s needs and constraints.
Final Thoughts and Further Directions
Throughout this article, we’ve experimented with the Data-Centric AI paradigm with a very hands-on, practical use case.
We started, as always, by understanding our data. We discovered, investigated, and solved particular data quality issues such as missing data, and improving our training data with synthetic data to overcome the imbalanced nature of the domain. Of course, for such a quick and simple case study, we focused on simple heuristics to get the job done, but the work of a data scientist never stop theres.
How would the results change if we considered a different imputation method? How could we have achieved a better fit in our synthetic data generation? Should we have balanced both classes equally or perhaps increase the representation of the minority class even higher? Could some feature transformation or dimensionality reduction helped the classification result? Should we have removed some cofounding features?
All of these questions seem unknowable at the start of any machine learning project. But as we start to measure and uncover the source of complexity in each dataset, we get better insights on what methods could improve classification results (a sort of “meta-learning” approach). And sure enough, the data needs to be manipulated and improved according to both the data characteristics and the ultimate goal of the project.
Producing a pre-defined pipeline and treating data preparation like a one-fits-all solution is similar to flying blind. Instead, a skilled data scientist continuously plays data detective and tries to find the best techniques based on the clues that the data leaves out for us to catch. And it usually does. We just need to keep our eyes sharp!
I hope you’ve enjoyed the tutorial, and as always, feedback, questions, and suggestions are much appreciated. Let me know what other topics you would like me to write about in the comments!
Getting Started with Data Science? Come and meet us next Thursday, November 23!
If you’re not part of the Data-Centric AI Community yet, you really should. We’re a friendly group of data enthusiasts that share a passion for learning data science. We occasionally organize some pretty awesome Code with Me Sessions, and we’re just kickstarting some super informal study groups.
I’ll be hosting the next one on November 23, 2023, where I’ll go through some Exploratory Data Analysis concepts.
See you there?
About me
Ph.D., Machine Learning Researcher, Educator, Data Advocate, and overall “jack-of-all-trades”. Here on Medium, I write about Data-Centric AI and Data Quality, educating the Data Science & Machine Learning communities on how to move from imperfect to intelligent data.
Developer Relations @ YData | Data-Centric AI Community | GitHub | Google Scholar | LinkedIn
A Beginner’s Guide to Building High-Quality Datasets for Machine Learning was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.